
You have 1 article left to read this month before you need to register a free LeadDev.com account.
Estimated reading time: 9 minutes
Here’s how the economics differ and important considerations to help you navigate that shift.
I’ve built over a dozen AI systems in production and every single one taught me the same lesson: the mathematics of AI economics don’t work the way we expect.
While we debate whether AI will replace jobs or boost productivity, we’re missing a more fundamental problem – the cost structures underlying AI applications are economically unsustainable.
Most businesses are building AI features assuming they work like traditional software, where marginal costs approach zero as usage grows. This assumption is mathematically wrong, and companies that don’t understand these cost patterns may find their unit economics challenging.
Your inbox, upgraded.
Receive weekly engineering insights to level up your leadership approach.
Traditional vs AI economics
The fundamental shift isn’t just that AI costs more, it’s that AI obliterates the economic advantages that made software businesses scalable in the first place. While traditional software achieves the holy grail of near-zero marginal costs at scale, AI applications face relentless direct costs for every single user interaction that never decrease with scale.
This isn’t a minor adjustment to existing business models. It’s economic disruption that forces a complete rethink of how software companies can actually make money.
The cost structure
Traditional software mastered the perfect economic model: massive upfront investment in development, infrastructure, and support, then essentially free distribution forever. Once built, serving another API call, page view, or feature interaction costs virtually nothing. Scale becomes your best friend.
AI-powered software shatters this model completely. You still face those same crushing fixed costs, but now every user action directly hits your bottom line. Every conversation, every query, every interaction consumes computational resources that translate to immediate, unavoidable API costs. The dream of “free tier” or “unlimited usage” models becomes an economic nightmare.
- Traditional software economics: Fixed costs dominate, marginal costs disappear
- AI software economics: Fixed costs crush you, variable costs never stop growing
AI creates something traditional software never had to worry about: extreme cost variance between users. While traditional software users all cost you roughly the same (nothing), AI users can vary by orders of magnitude.
A casual user asking simple questions might cost you pennies. A power user diving into detailed multi-turn conversations with agentic workflows can rack up costs that would make your CFO weep. Some users literally cost 100x more than others to serve.
Why “grow now, monetize later” doesn’t work with AI
This fundamental shift makes the classic venture capital playbook “grow now, monetize later” more dangerous. In traditional software, growth means spreading fixed costs across more users while marginal costs stay negligible. Growth makes you more profitable.
With AI applications, growth directly increases your largest expense category. Every new user potentially makes you less profitable. The faster you grow without nailing unit economics, the faster you burn cash.
AI companies can’t rely on scale to save them. They need sustainable economics from day one, or growth becomes a path to bankruptcy rather than success. This isn’t just a pricing problem, it’s an entirely new category of business model challenge that requires fundamentally different strategic thinking.
More like this
Subsidized API pricing
Current API pricing reflects market dynamics that may shift as the industry matures. Understanding the underlying economics helps plan for potential changes.
Scaling laws and training economics
The scaling laws for natural language models (Kaplan et al.) show that increasing compute creates diminishing returns that make each model generation more expensive for marginal improvements.
Performance ∝ Compute^α where α < 1
Training costs between models of different generations:
- GPT 5: >$500 million to train [Source]
- GPT 4: >$60 million to train [Source]
- GPT 3: ~$4.6 million to train
Each generation costs 10x more for at best 2x performance improvement. The mathematical progression is unforgiving: 10x training cost yields 2x performance improvement, 100x training cost yields 4x performance improvement.
Understanding cost pressures
Current operational costs are substantial. Business Insider reported that ChatGPT costs approximately $700,000 daily to operate, extrapolating to $255 million annually just for inference costs. This number has vastly increased in recent months or years. These figures help explain why API pricing reflects not just current operational costs but also training cost recovery and future development investments.
Companies building long-term roadmaps should consider that API pricing may need to reflect true operational costs more directly as the market matures and venture subsidies decrease.
This gap exists because venture funding subsidizes the difference. OpenAI, Anthropic, and Google burn billions to maintain artificially low API prices that enable the current AI ecosystem. When these subsidies end, API pricing must increase massively to reflect true costs, or providers accept unsustainable losses indefinitely.
The performance-cost trade-off
This creates a product development challenge: optimizations that make AI affordable can reduce its usefulness, while features that enhance utility can worsen unit economics. Companies can get caught between improving user experience and controlling costs.
| Cost Reduction Method | Cost Impact | User Experience Impact | Potential Issues |
| Context compression | High | Responses lose conversation memory | Users repeat information |
| Response length limits | Medium | Truncated answers | Users ask follow-ups, increasing total costs |
| Cheaper model switching | High | Lower quality responses | Users retry queries, negating savings |
| Conversation restarts | Very High | Forced conversation resets | Users start new sessions |
| RAG instead of full context | Medium | Less contextual understanding | Answers may feel less personalized |
Traditional product development followed: better experience → more users → more revenue
AI product development operates under different mathematics: better experience → higher costs → unit economics challenges
Token cost patterns
The first economic reality that affects most AI business models lies in the token cost that compounds with conversation length. This matters more than any other pricing factor when building AI applications.
Cost Formula Derivation
Understanding AI conversation costs requires recognizing that each turn must include the entire conversation history. Here’s how the mathematics work:
Let’s define our variables:
- I = Avg. input tokens per turn (user message)
- O = Avg. output tokens per turn (AI response)
- P_i = input price per million tokens
- P_o = output price per million tokens
For the nth conversation turn:
Input tokens needed: I + (n-1) × (I + O)
- Current input: I tokens
- Previous conversation history: (n-1) × (I + O) tokens
- Avg. Output tokens generated: O tokens (constant per turn)
This gives us the cost formula for the nth conversation turn:

For the total cost across N conversation turns:
From this formula, these critical relationships emerge:
– Cost ∝ P_i x N² (quadratic scaling with conversation length and linear scaling with input token price)
– Cost ∝ P_o x N (linear scaling with output token price, conversation length)
Three factor cost impact analysis
These relationships reveal the three factors that matter most for controlling costs. Let’s examine each one, starting with model choice.
Model Choice Impact
At enterprise scale, with substantial daily conversation volumes, model selection creates the largest absolute cost differences across providers:
| Model | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Multiplier |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 5x |
| GPT-5.1 | $1.25 | $10.00 | 8x |
| Gemini 3 Pro | $2.00 | $12.00 | 6x |
| GPT-5 mini | $0.25 | $2.00 | 8x |
Model choice creates the most significant budget impact. The cost difference between the most economical and premium models can represent millions in annual expenses for enterprise applications.
Higher-tier models like Claude Sonnet 4.5 ($3.00 input/$15.00 output per 1M tokens) cost 12x more than budget alternatives like GPT-5-mini ($0.25 input/$2.00 output per 1M tokens) while delivering only incremental performance improvements for many use cases.
Cost formula reveals something important regarding model pricing asymmetry:
For short conversations (where the number of turns N is small), the quadratic input-cost term N² stays negligible. As a result, the linear term Pₒ × N × O dominates the overall cost.
- This means the output token price (Pₒ) has the biggest impact.
- Therefore, models with low output pricing are the most cost-efficient for short exchanges. (Example: GPT-5 mini)
For long conversations (where N becomes large), the situation reverses. As N² grows, it quickly overtakes all other components of the cost equation. At that point, the main driver becomes Pᵢ × N², the input-side cost.
- Here, the input token price (Pᵢ) matters far more than output pricing.
- For extended chats, models with low input pricing provide the best value. (Example: Use GPT5.1 as compared to gemini 3 pro even though both have similar output token pricing)
This explains why model choice strategy should also differ based on expected conversation lengths.
Output Length Scaling Impact
Output length refers to how verbose the AI’s responses are, measured in tokens (roughly 0.75 words per token).
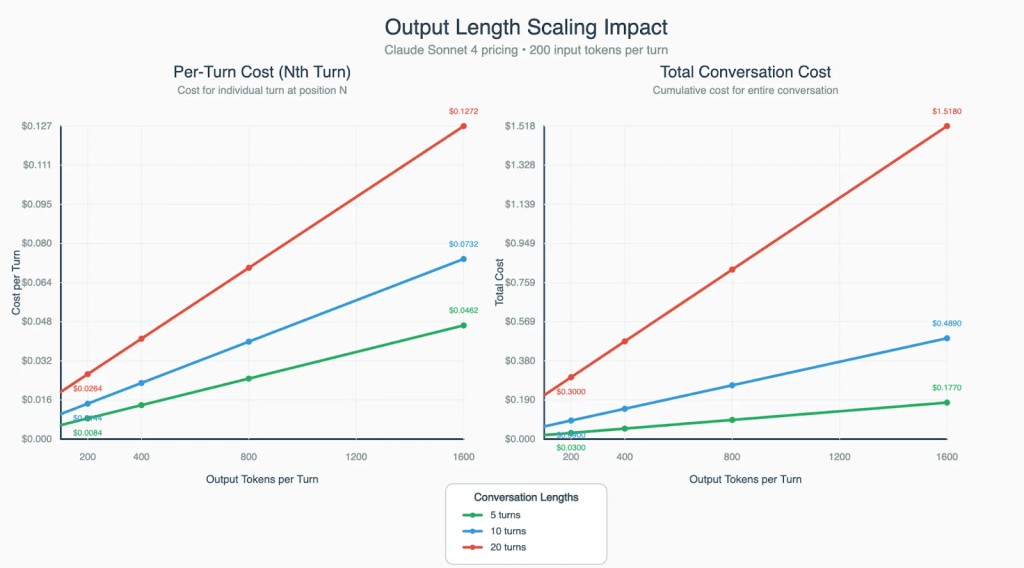
Output length scales linearly, but its impact on total cost is small. In multi-turn conversations, the model spends far more money reprocessing the entire conversation history than generating a longer response. This means that asking the model to “keep answers short” barely reduces cost. In a 20-turn chat, reading those 20 past messages costs significantly more than making the current reply even twice as long.
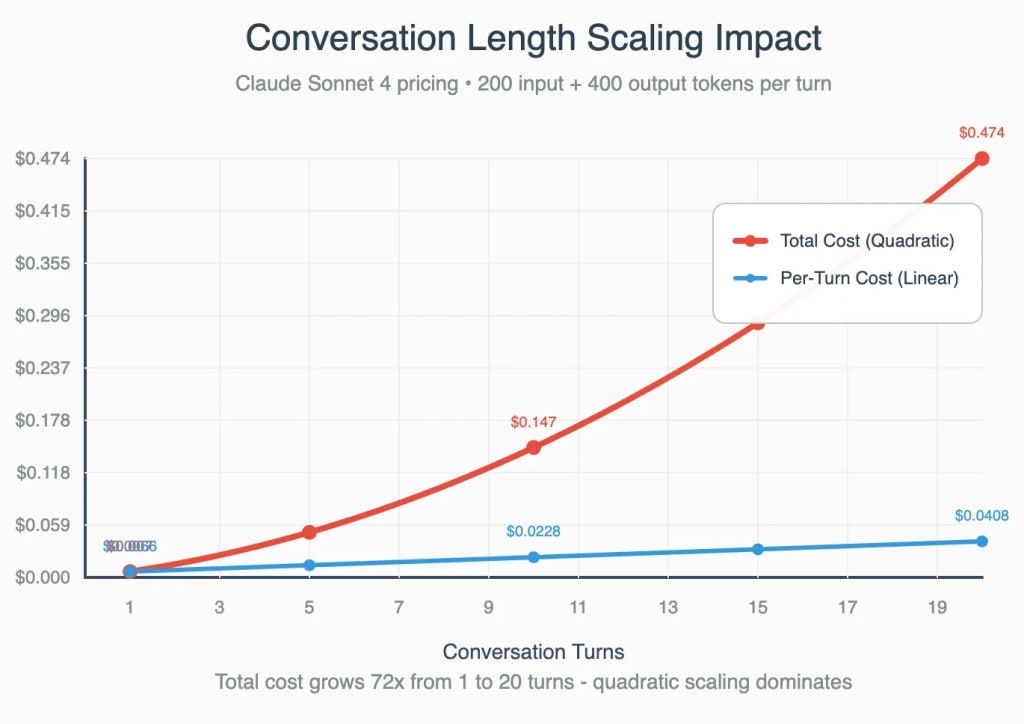
Conversation Length Scaling Impact
The most economically critical cost factor when working with AI models is conversation length, as it creates quadratic cost growth.
Conversation length scaling follows quadratic mathematics, meaning the cost doesn’t grow linearly, it accelerates. Each new turn requires the model to reread all previous turns, so the total tokens processed follow the pattern 1 + 2 + 3 + … + N ≈ N²/2. That’s why a 40-turn conversation costs roughly four times more than a 20-turn one. This quadratic reprocessing overhead quickly dwarfs output length, verbosity, or model choice, making conversation length the single most important factor for sustainable AI application design.
Agentic AI cost scaling
Agentic AI systems multiply costs because every tool call requires the model to reprocess the full conversation context. In a normal chat, the model reads the entire history once per user turn. In an agentic workflow, it may need to read that same history three, five, or even ten times to plan, call tools, interpret results, and generate the final answer.
A simple way to think about it:
Cost of standard chat:
O(N²)
Cost of agentic chat:
k × O(N²), where k = avg. number of tool calls per turn
Even a small k (like 3–4) makes a long conversation dramatically more expensive. This is why agent systems feel powerful but become difficult to scale economically, each step compounds the quadratic context cost you were already paying.
Designing sustainable AI products
Users don’t buy tokens, they buy outcomes. This asymmetry between user value perception and computational cost becomes the primary lever for managing AI economics.
Intelligent resource allocation
Build systems that dynamically allocate AI resources based on value potential. High-value interactions (new customer onboarding, revenue-generating activities, complex problem-solving) get premium AI models, while routine interactions (FAQ responses, simple queries) use optimized alternatives.
Users experience consistent quality because you’re optimizing for their outcomes, not your costs. Behind the scenes, you might use Claude Sonnet 4 for the sales proposal and GPT-4o-mini for calendar scheduling. Instead of limiting what users can do, design constraints that enhance experience, for example a “smart summary” feature naturally limit response length while feeling premium and highly useful.
Smart context management
The quadratic scaling problem stems from treating all conversation history equally. But different types of information serve different functions within conversations.
- Decision relevant information (user preferences, established facts, current objectives) maintains value throughout extended conversations.
- Process information (reasoning chains, intermediate steps) serves immediate needs but loses utility quickly.
- Reference information (documentation, system instructions) provides consistent utility but doesn’t require reprocessing.
Preserve decision context, compress process context and cache reference context. This makes quadratic scaling manageable while maintaining conversation continuity for users.

New York • September 15 & 16, 2026
The pace of change keeps accelerating. See what other leaders are doing about it, at LDX3 New York.
Price for value, not consumption
Balance your user base strategically: light users who are profitable at scale, and power users who justify premium pricing despite higher costs. Design pricing around outcome complexity rather than usage volume. When pricing reflects what users accomplish rather than computational costs consumed, the underlying mathematics work in your favor instead of against it.
Successful AI businesses will be those that master the art of delivering consistent user value while intelligently managing the underlying economic realities of AI at scale.




