
You have 1 article left to read this month before you need to register a free LeadDev.com account.
Estimated reading time: 6 minutes
What if your support process quietly costs more than the customer you’re keeping?
We obsess over churn rates, retention metrics, and glowing customer satisfaction (CSAT) scores. Yet, we rarely measure what customer support actually costs, especially when issues escalate to engineering.
It’s the Pareto principle applied to customer support: roughly 80% of consequences come from 20% of causes. Routine questions about billing, onboarding, and “how-to” queries make up a large portion of support volume and get handled efficiently. But technical questions, bugs, security vulnerabilities, edge cases, and outages? While these issues are less frequent, they are exactly the high-impact cases that make costs spiral, involve multiple teams, and cost hours of engineering time.
Every engineer has lived through at least one multi-day (or multi-week) coordination nightmare caused by a critical bug hitting a customer. Just getting everyone on the same page can take hours of back-and-forth between various stakeholders.
Despite this we’re seeing an explosion of customer service AI agents designed to handle routine tickets faster. Meanwhile, the debugging workflows that engineering teams follow to resolve these high-cost, high-stakes issues remain largely untouched.
We’re optimizing the 80% of issues that cost very little, while ignoring the 20% that cost the most.
Your inbox, upgraded.
Receive weekly engineering insights to level up your leadership approach.
The hidden costs
The cost of resolving a technical issue depends on two interconnected things: engineering cost and business impact.
Engineering cost is determined by technical complexity. This includes issues deep in system architecture, problems spanning multiple services, and intermittent bugs that are hard to reproduce. It also involves code in legacy systems that is poorly understood and fragile to change, or issues requiring cross-functional coordination.
Business impact depends on who’s affected, how many users, and what’s at stake: SLA breaches, potential data loss, churn risk, revenue loss.
Engineering leaders instinctively triage issues along these two dimensions:
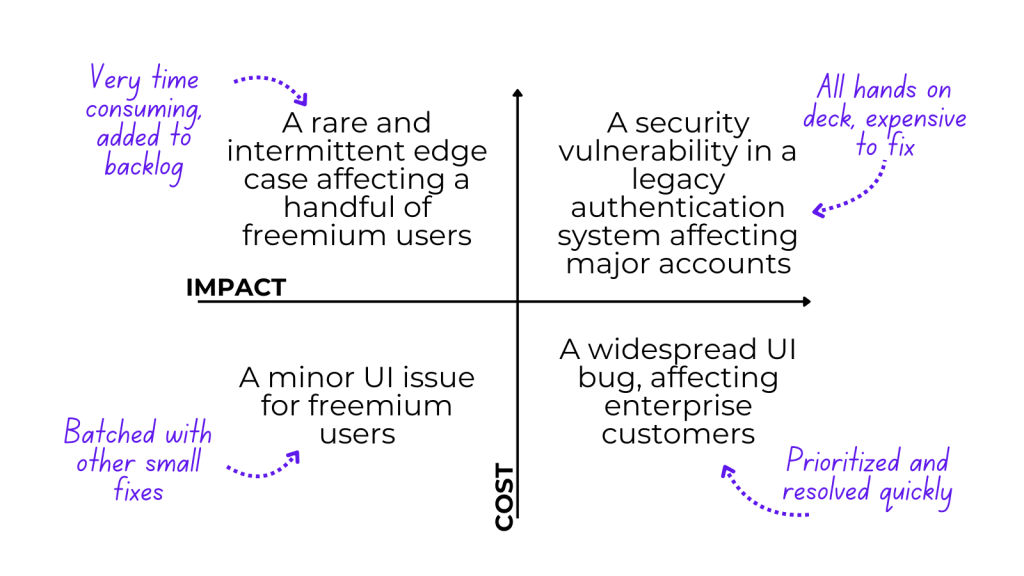
But here’s the problem: this triage exercise is built on guesswork. Oftentimes it’s hard to estimate how expensive an issue will be until you understand the root cause and all its ramifications. And even when your instincts are right, it’s extremely difficult to put a number on what “expensive” actually means.
That’s because the debugging workflow itself is chaotic and unmeasured. It’s a multi-person relay race through a maze of Slack threads, Jira comments, email chains, and dashboard exports. Each handoff burns time and context. Hours disappear to context-switching, timezone delays, and slow-motion alignment meetings.
These hidden costs that don’t get measured quickly add up and affect your bottom line.
More like this
How support costs snowball
Jeremy Battlees, CEO of FilingRamp and a Multiplayer customer, describes a common scenario in a recent call: “Debugging for us was always a slow process. We had to dig for information across multiple systems.”
We intuitively know that feature-rich applications with hundreds of components, microservices, and APIs are complex to debug. Especially when technical sprawl mirrors a multi-team org chart. But even for “low-impact” cases, resolution costs stack up fast.
Take a minor bug as an example: an intermittent “save” issue affecting a single user. Not an outage, just something that prevents them from fully relying on your product.
Here’s what that journey typically looks like:
- A support ticket is opened. The customer success engineer exchanges messages with the user, trying to reproduce the issue.
- The ticket is escalated to engineering, where the first challenge begins: reproduction. Engineers request device details, browser metadata, screenshots, maybe a video, often through multiple back-and-forths.
- Once enough context is gathered, engineering starts investigating. Frontend passes it to backend, backend to infrastructure. Whoever takes ownership spends hours pulling traces, parsing logs, and cross-referencing dashboards just to see what actually happened.
- A product manager may get pulled in to confirm whether the behavior is expected, to approve a UX change or to confirm if the fix affects another feature.
- Meanwhile, parallel conversations unfold: the customer checks in for updates, escalation managers join threads, “sync” meetings are scheduled to ensure alignment.
- Finally, the fix reaches QA, who discovers an edge case. And, the loop starts again.
We like to imagine technical support as a linear process: user reports bug → support logs it → engineers investigate → fix is deployed → customer is satisfied.
But the reality is much more convoluted, with each step burning hours across multiple teams. Every extra hour multiplies the cost of what began as a “minor bug.”
Now imagine this workflow for a critical security vulnerability affecting your largest enterprise customer.
Let’s dive into the math
Using global median salaries from the 2025 Stack Overflow Developer Survey, and assuming a 40-hour workweek with 20 vacation days, we can estimate the following hourly costs:
- Frontend developer: $32/hr
- Backend developer: $42/hr
- Developer QA & Test: $30/hr
- Product Manager: $52/hr
- Customer Success / Support engineer: $33/hr
If we revisit the workflow from the previous section and (optimistically!) assume only two hours of involvement per person, that single “minor” bug already costs around $377 in internal time. And that’s the best-case scenario.
Harder-to-debug problems require multiple rounds of investigation, additional stakeholders, and coordination meetings. Costs quickly climb into the thousands per issue.
This is the economic sinkhole most teams never quantify. Each bug looks small in isolation, but collectively they create a massive, invisible drain. It doesn’t show up on dashboards or CSAT scores, yet it silently consumes more value than it protects.
The true cost compounds as you scale:
- Knowledge fragmentation: As your platform grows and team members come and go, no single person understands the entire system. You need more people in the loop just to diagnose what failed.
- Coordination overhead: Add the stakeholders we didn’t count (Account Executives, Escalation Managers, Solution Architects, etc.) especially for enterprise customers.
- Opportunity cost: Engineers pulled from roadmap work. Delayed releases. Lost focus. Slower product velocity.
At scale, debugging inefficiency is a hidden flaw in your business model.
The real bottleneck is correlation
The core problem isn’t that your team is unresponsive or your engineers aren’t skilled. It’s not even that you lack observability tools. In fact, over half of companies use six or more observability tools, with 11% using 16 or more.
The problem is correlation: connecting frontend to backend, customer experience to affected services, user actions to system behavior.
Most engineering workflows remain siloed. Session replay tools capture user behavior and live in the PM’s toolkit. Observability platforms capture backend telemetry and belong to DevOps. Error monitoring tools straddle teams. Each tool is designed for a specific use case, used by a specific team, and stores its data separately.
The result? Tool sprawl meets data fragmentation. Correlating information across stack layers requires constant context-switching between platforms, Slack channels, and dashboards. Engineers spend 30-60 minutes per issue just manually stitching together what should be unified from the start.
This fragmentation also limits AI effectiveness. It’s why AI-generated code often looks correct but fails at runtime. It’s missing critical context about how systems actually behave in production. The promise of AI-powered debugging can’t be realized when the data it needs is scattered across a dozen tools.
The solution?
The simplest way to reduce engineering costs is giving everyone (support, product, engineering, QA) the same complete view of what actually happened, instantly. Not just logs. Not just frontend replay. Not just backend traces. All of it, correlated, in one place.
I’ve spent years watching this play out: engineering teams burning days on bugs that should take hours, constantly context-switching between six different tools, manually correlating fragments. It’s even why I built my company, Multiplayer, around full-stack session recordings that auto-correlate frontend with backend data.
Once you have that unified context, AI tools can finally deliver on their promise: finding root causes faster, suggesting fixes with full system awareness, and turning what used to take hours into minutes.
AI agents have the potential not just to revolutionize customer support, but also the far more expensive work of resolving technical issues. But only if we first solve the correlation problem that’s been holding us back.

New York • September 15 & 16, 2026
The pace of change keeps accelerating. See what other leaders are doing about it, at LDX3 New York.




