You have 1 article left to read this month before you need to register a free LeadDev.com account.
When building an application or company, engineers always start small.
There isn’t a customer base. The team can move pretty quickly. We build things overnight. We just keep adding. And it feels great. Everything seems so easy.
Then you have users and customers, and that’s even more exciting, because we built the things to be used. But users have expectations. They have desires for specific features. What do we do now?
Building features quickly and safely
Things are getting more complex. We’re adding and, at some point, it gets a little crowded. Now we are facing two options: keep going fast and break things, or pace ourselves.
Really, though, we want to build things fast and safe. To do that, we need to break down what velocity and risk actually mean.
Reduce waste, optimize velocity
Velocity is value added over time. It isn’t necessarily code, as code doesn’t add value per se. You have to think in terms of business value. How much value do we keep adding over a certain period of time? This is what needs to be optimized.
Pushing more hours onto engineers is rarely effective. Your team might see some initial gains, but it’s not sustainable and eventually is counterproductive.
To optimize productivity, a team has to reduce waste. This has been advocated through “Lean” methodologies for quite some time. In more practical terms, below you can see eight key different areas of waste reduction. It’s an acronym: DOWNTIME.
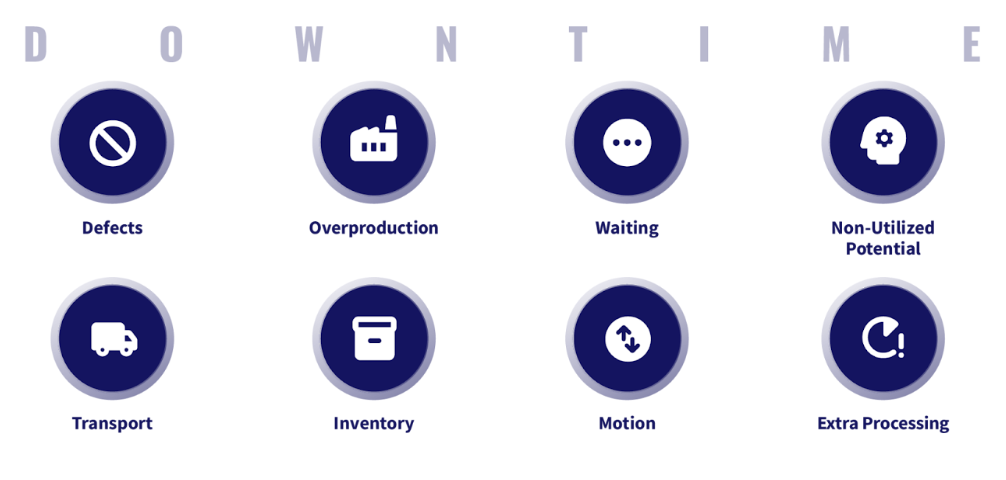
You can look at each of those in detail, but there’s a lot of surface and not everything will give you the same amount of gains. In my experience with product engineering teams, there are four key sources of waste to focus on.
Key sources of waste
Lack of clarity
Having clarity over product scope makes a huge difference in execution. The same group of engineers moves very differently when the product direction is clear versus when it is still evolving and searching for a path. It also goes a lot faster when responsibilities are clearer and goals are precise. To gain this, the question I always ask is, “Is there some element of clarity that would help the team have a better understanding and move faster?”
Doing too much
Many of us have great product ideas: different aspects, corner cases, and other options. However, our brains tend to be additive. It’s difficult to identify what is core and essential. I, like many of you, get attached to ideas. But, in reality, they don’t all need to be there, especially from the start. It is important and impactful for velocity to go iteratively, built upon smaller projects, collecting value earlier.
Too many dependencies
One very common velocity inhibitor is dependencies. They can be in code, in tasks, between people, and/or in processes. Each dependency creates a delay. If a dependency is necessary, ask how it could be coupled more loosely. Imagine two people running while attached to a rope. The tighter the rope, the slower they get. And, of course, they will never be as fast as if they run fully independently.
Not measuring enough
It’s often difficult to understand the impact surrounding new features: Are they making things worse or adding value? Creating faster feedback loops makes people move better. Nothing drives better behavior than measurement.
Assessing risk
Risk is the chance that something bad happens to something of value. In other terms, you can express it as:
Risk = asset at risk (revenue, users, …) * issue duration * issue impact radius * issue probability
Assets: This is everything that makes your company valuable. It can be revenue, users, customers, employees, trade secrets… When you’re in the early stages of a company, you have less to lose. This is why bigger companies often move slower; because they tend to be more risk-averse.
Issue duration: This is the time it takes to detect an issue, respond, and resolve it. It’s often a matter of detecting things earlier. When your alerts are too sensitive, things get too noisy and people start ignoring them. Find the balance between responsiveness and noise.
Impact radius: How many of your users are affected by the issue? How broad is your impact? Is it one customer, a few, or all of them that are affected? There are different ways to address this. One move is user and customer isolation: If you separate them, then you can impact fewer of them. Granted, this requires more complicated management tools. Other tools that can help limit impact radius are progressive rollout and A/B testing.
Issue probability: This is defined by the number of unknowns you have. Changes can be more or less complex and therefore have different inherent issue probabilities. The bigger the change, the bigger the risk.
Those are the four elements you need to manage. I find it’s better to tackle smaller and more isolated changes. If you deploy 50 changes at the same time, it’s much more risky than doing a deployment for each change. However, you have to balance the ROI of testing, which becomes pretty low once you reach a certain point.
Start by reducing complexity. One way is to focus on building modular code. Microservices allow for simplifying the context with a change as they have clearer dependencies, boundaries, and interfaces, making it less likely that a change will have unexpected side effects.
Then I encourage keeping your house clean by removing low-value features. I often see dead code that adds to feelings of confusion.
Drive velocity and manage risk all at once
Here at Split, we believe that pairing feature flags with measurement and statistical analysis solves many of the issues and challenges I’ve addressed.
By using feature flags we can better decouple the activation of changes, reducing the risk for deployments. It also enables each team to do progressive rollout by segmenting users for controlled rollouts, which limit overall exposure to risk.
While controlling your exposure progressively is great, it’s less effective if there aren’t associated measurements.
I have seen companies doing rollouts in this way, but they wouldn’t detect anything until they had rolled out to 100% of the user population. At that point, progressive rollouts are more to feel good than to make good. If you associate measurement with your feature flag, and do causal analysis using statistical methodologies, you can have clear measurement by segment of population and get confidence in the difference between the populations.
Now, it becomes clear when it is safe to move forward with a progressive rollout and when something is off. There is a clear and early feedback loop that includes root cause analysis. We can take action or dig deeper into the reason behind it without a guess.
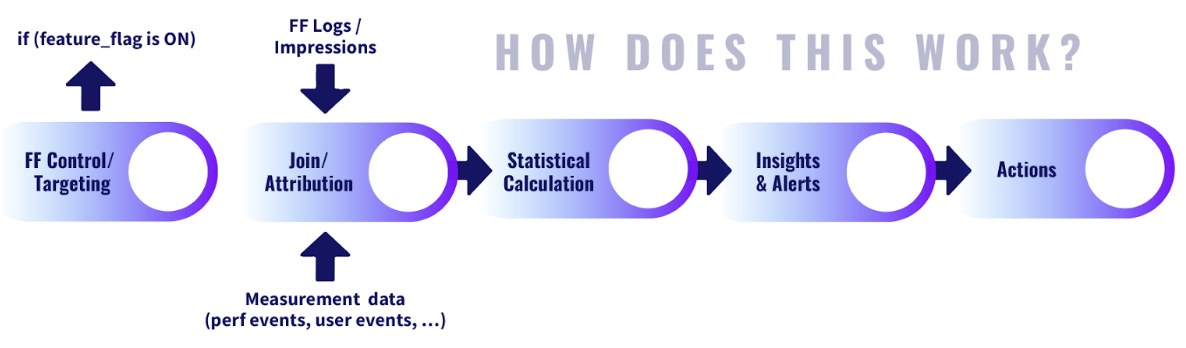
Increasing velocity and lowering risk doesn’t have to be a trade-off. Implementing feature flags with causal analysis is, from my experience, one of the most effective ways to gain on both fronts.
Promoted Partner Content





