
You have 1 article left to read this month before you need to register a free LeadDev.com account.
Ensure a project’s success even if you’re not a domain expert.
As a technical expert, you can find yourself automating parts of a job you have no experience doing.
I was in this position recently. I worked with a team of psychologists who had developed a workplace personality assessment, and they wanted to generate the reports with AI automatically. I know nothing about psychology, and yet I needed to ensure these AI-generated reports were error-free and met ethical standards in a highly regulated domain.
Further complicating the issue was that the client had developed specialized language and a proprietary framework for writing their personality reports, which was hard for me to understand. After each report was generated we had to check whether each term was used correctly, and there were specific phrases that needed to be used in certain circumstances.
As a prompt engineer, it was my job to A/B test changes to the 19,000-word prompt we used with GPT-4o to generate the report. Here, the aim was to minimize errors needing manual review.
Working with non-technical stakeholders
AI is a fast-moving field, and there are always several misconceptions or myths that I need to dispel whenever I start a new project. If your stakeholders have the wrong mental model of AI, they will have unrealistic expectations about the results.
Hallucinations
AI models tend to confidently make things up, dubbed “hallucinations.” It’s impossible to completely eliminate hallucinations because it’s core to how AI models work. They respond with the most likely answer based on your prompt and how often these words appear together in the model’s training data, but they don’t “know” if that answer is correct or not.
The model doesn’t know Mary Lee Pfieffer South without the context of Tom Cruise, because she is only ever written about online as Tom Cruise’s mother.
It is important to sit down with the domain expert to understand how the AI model is miscalculating. Refuse to accept general feedback from them like “the the AI gets it wrong,” or “it’s too verbose,” and instead ask for specific instances. Drilling down into multiple examples helps to paint a better picture of what the LLM is getting wrong, how often, and how important each issue is. Keep a spreadsheet log of the issues you identify, and ask the domain expert what a better response looks like for each issue.
Many issues will arise. Some are more easily solved than others. In my case, errors identified in the personality reports were simple formatting inconsistencies that I solved with regular expression (regex) rules.
Other, more complex, issues related to the LLM’s interpretation of the client’s proprietary psychology language and framework. After I reviewed the prompt line-by-line with the domain, we found that we weren’t explaining our parameters clearly enough in the prompt.
Working with a domain expert to document and categorize common hallucinations and other issues from LLM-generated output is key to progress. You can’t rely on your intuition when dealing with an area where you have no domain expertise because AI models are good enough that their mistakes will be subtle.
More like this
Temperature
Another aspect of generative AI that isn’t intuitive to non-technical stakeholders is that LLMs are non-deterministic. This means you get different results every time you run the same prompt. This is governed by a temperature parameter, which determines how much “randomness” is injected into the choice of each next word. Any temperature closer to 0 makes the response almost the same every time (it always chooses the highest probability word), but the creativity of the response is somewhat constrained. With a temperature closer to 1, the model chooses from a range of probabilities.

Caption: The model chose the word “perfect” which had a 3.69% probability, rather than the obvious choice of “fit” which had an 84.38% probability.
The psychologists automating their personality test reports were already optimizing the temperature parameter by adjusting its value (0 to 2) and observing how it influenced the results. They had settled upon a value of 0.67, which seemed to get the most consistently good results.
However, even when I hadn’t made any changes to the temperature or prompt, the stakeholders frequently reported that performance had gotten worse – they had just been unlucky in getting a few bad reports in a row. What they should have done is run the same prompt with the same temperature multiple times before making a judgment on whether the performance was good or bad.
To balance out this problem, we adopted a more rigorous test-and-learn approach. We A/B tested each prompt change 10-30 times, measuring the average number of issues generated in the reports. This smoothed out the randomness and told us whether things were actually getting better or regressing. Think about flipping a coin and getting three heads in a row. There’s a 1 in 8 chance of this happening, so you shouldn’t conclude the coin is biased unless you get ten heads in a row, which only has a 1 in 1024 chance of happening. If you run your prompt three times and get three bad results, it doesn’t necessarily mean something is wrong: run it ten times, and you may see that the next seven results are all good.
This A/B testing process became invaluable when we switched models from GPT-4 to GPT-4o, as it gave us confidence that the new model performed at the same level while being five times cheaper.
Training the AI model
The client explained how, initially, an AI expert helped them “fine-tune” the model to improve performance. It turns out they were actually tweaking the prompt and not using fine-tuning. This was a reminder that non-technical stakeholders often use technical terms loosely, so don’t make assumptions about meaning.
Prompt engineering requires communication and writing skills to write concise and clear prompts, as well as an iterative approach to testing. Although prompt engineers often dabble in fine-tuning (and I did test it for this client), prompt engineering is usually quicker and easier to get started with because it doesn’t require you to build up a large training dataset and understand machine learning code. Studies show that you need 2,000+ examples of the task being done correctly before fine-tuning beats prompt engineering, which can take time if your domain expert is writing them manually.
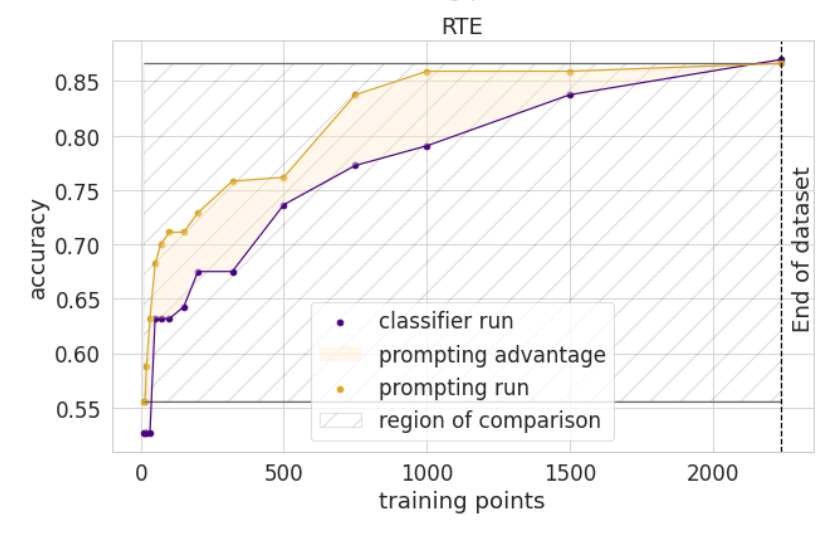
Prompting beats fine-tuning under 2,000 examples. Source: “How Many Data Points is a Prompt Worth”
Fine-tuning is better suited to machine learning engineers when working on tasks where the model has thousands of examples to learn from. Finding someone who really understands what is happening under the hood and tweaks the approach to get the best performance is a rare and expensive skill to hire.
Efficient data-gathering strategies
Trained and licensed psychologists are busy, and their time is valuable. So, I developed a formal system for evaluating LLM outputs that made the most of limited human feedback.
I created “LLM judge” – another prompt that ran after the first one to identify any issues with the final personality report. This reduced domain experts’ review time from one day a week to one day a month, a 75% reduction in time spent.
We ran our LLM judge after every A/B test, and it identified how many issues occur on average in all reports generated. This expanded the scope of our testing from one test a week to two to three a day, eventually finding a prompt that generated 62.5% fewer issues per report, saving countless hours of manual review.
Because LLM judges are just another prompt, they also make mistakes. It’s important to evaluate the accuracy of your LLM judge by working with your domain experts to build up a set of test cases. Find examples of issues in past reports and see if the LLM judge can correctly identify them when they occur again in the generated reports.
It’s also useful to get your domain expert to “correct” each issue from past reports separately so you have before and after examples. This way, you can identify false negatives (where the AI misses a present issue) by running the LLM judge on reports a domain expert has marked as incorrect. You can also identify false positives (where no issue is present, but the AI thinks there is) by running the LLM judge on the version of the report that a domain expert has corrected.

Key takeaways for senior engineers leading AI projects
AI has a lot of promise, but the majority of projects are still in the prototype phase; the models and techniques are always changing. Not only do you have to ensure you explain jargon and technical terms accurately, but you also set realistic expectations about what AI is good at and what techniques might help. Staying up to date with the latest developments in the field is a huge boost.
Making progress in a field, even if you have no experience in it, is possible. By working effectively with domain experts to train an LLM judge you can teach AI to be able to predict what the domain expert would say, helping you iterate faster to improve performance through A/B testing. Automating expert feedback using AI in this way can significantly decrease the time experts have to spend each week grading results, making you a champion within a non-technical organization.




