
You have 1 article left to read this month before you need to register a free LeadDev.com account.
Your inbox, upgraded.
Receive weekly engineering insights to level up your leadership approach.
Estimated reading time: 7 minutes
As more and more products integrate AI, there is a need to efficiently manage the data, as well as quickly retrieve it. Enter vector databases.
Vector databases can deal with large volumes of unstructured data like text, images, and audio. They are scalable and efficient for real-time querying, making them ideal for search-based applications. These qualities also make vector databases uniquely suited to customer support, healthcare, and personalization use cases.
Think of a chatbot on your website that answers questions from potential customers by leveraging a vector database trained on product documentation, tutorials, FAQs, and other knowledge bases. Or an AI-powered assistant for customer support agents that can quickly pull information from past email and chat interactions, previous troubleshooting activity, and similar support tickets across multiple languages to help resolve an issue.
Let’s take a look at the underlying foundations of this emerging technology.
What is a vector?
A vector database leverages the power of vector mathematics to store and retrieve data. Vectors are mathematical objects that have both magnitude and direction. In a world without maps on your device, if you had to travel from point A to point B, the two pieces of information that you would need would be the distance and the direction, which together form a vector.
In other words, your journey from A to B can be visually represented as an arrow. The length of the arrow would be the distance you traveled, which in the case of a vector is its magnitude. The tip of the arrow would indicate the direction, for example ‘north-east’.
What is a vector embedding?
Consider a point on a sheet of paper. It can be represented by an x coordinate along the width, and a y coordinate along the length. In the field of information retrieval, data can be represented as vectors in a space with multiple dimensions. Depending on the dataset and the attributes present, these dimensions could represent features like price or shape or temperature.
These vectors that capture the semantic meaning of text are called embeddings. Embeddings convert text into numbers while retaining their contextual information. They encode the information about the meaning and the relationships present in the data.
In the context of large language models, words related to each other will be located closer in the vector space model. For example, ‘leader’ and ‘manager’ will have a lower distance, or higher similarity between them, compared to ‘leader’ and ‘pasta’. Similarly (pun intended) ‘cake’ and ‘baking’ will have a high similarity score, as opposed to ‘cake’ and ‘racing’.
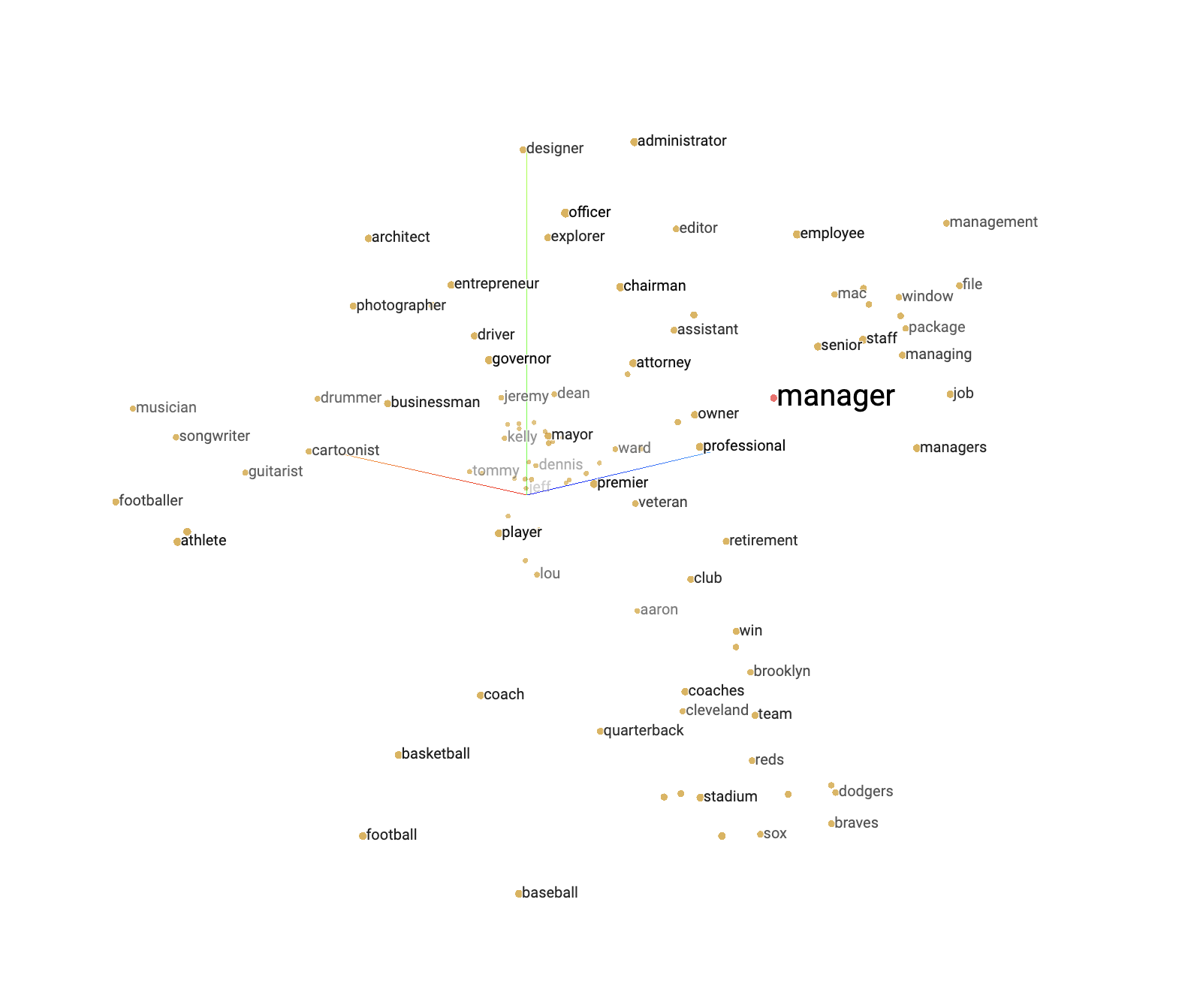
Neighboring words for ‘manager’ in the vector space model from Tensorflow’s Embedding Projector
This concept is applicable to not just words, but also sentences and documents. In fact, search engines utilize embeddings for semantic search. The embedding of a user query is compared to the embeddings of documents in the dataset to find relevant results. This allows finding documents that are semantically similar to the query, even if the same keywords are not used in the documents. While text-based embeddings are the most common, this approach also applies to other types of data such as images and audio.
More like this
Vector database vs relational database
Traditional databases, like relational databases, work with structured data where the schema is known. Used commonly for transactional workflows, these databases use structured query language (SQL) to find exact matches for keywords and values across rows and columns.
Vector databases operate on unstructured data and store the data as vector embeddings which capture the semantic meaning of the data. For instance, a query for ‘suggest recipes for a snowy day’ would return recipes for soup, even though there is no word overlap between the two. Or a customer could say ‘I recently ordered boots but they don’t fit me well’ and receive details about a store’s exchange and refund policy, despite those exact words not being in the data. The embeddings present in the vector database help understand the context and relationships among words, leading to relevant results.
Consider using relational databases when dealing with transactional data or when looking for exact matches. Vector databases are a good choice for large volumes of unstructured data where finding semantic similarity is important.
How does a vector database work?
Data storage
A machine learning model acts as an embedding model and transforms the data into embeddings. Embeddings can also be generated through handcrafted algorithms, though the common way is to use existing models or APIs from providers like Hugging Face and OpenAI. These embeddings are then stored in the vector database. Metadata like title or description can also be stored to help refine search or provide additional context for the embeddings.
Vector databases leverage indexes for quicker and more efficient search. The embeddings are mapped to a special data structure, like a hash table, which enables faster searches. These indexes are similar to an index present in a book that allows a quick lookup of pages related to particular topics.
Data retrieval
Once a user performs a query, the query is converted into a vector embedding using the same embedding model that was used for the ingested data. The database performs a search using the approximate nearest neighbor (ANN) algorithm to retrieve the most relevant results. This is done by comparing the query embedding with the data embeddings to find results similar to the query based on similarity or distance metrics.
ANN uses approximation to find ‘close enough’ matches in the vector database. This fast retrieval gives vector databases an edge over the traditional databases with slower search algorithms. Since the data is already stored as embeddings, this is computationally efficient, leading to quicker results. The relevant embeddings can then be mapped back to their original content.
Post-processing
Oftentimes, the vector database performs post-processing to refine the results to improve the accuracy. A type of post-processing is ‘metadata filtering’ in which the results are filtered based on the metadata of the nearest neighbors.
For example, ‘availability’ might be an attribute present in the metadata, and items out of stock would get filtered out. Another common approach is reranking which reorders the results using properties such as recency, user preferences, etc. The goal of post-processing is to enhance the relevance of the results and improve the user experience.
The pros and cons of vector databases
Vector databases are designed to be quick and efficient, resulting in lower latency and higher performance. They can handle large datasets and are scalable. Multiple types of data, including text, images, and audio are supported, making them versatile for different tasks. Because of the use of embeddings, vector databases can detect hidden patterns and relationships that a traditional database would not be able to infer.
While vector databases can be powerful, they come with certain caveats. Running similarity search algorithms for large datasets can be computationally expensive, impacting performance adversely. Processing large volumes of data for ingestion can be time-consuming and storing the high-dimensional vectors requires significant memory. As vector databases use an approximation algorithm, the accuracy is traded off and exact match queries are not supported.
The applications of vector databases
One of the most successful applications of vector databases is within a Retrieval Augmented Generation (RAG) framework for AI applications. A user sends a prompt to the AI application which includes a query. RAG utilizes a vector database to retrieve documents relevant to the user query and appends this information to the prompt and the query. These documents provide additional context and help augment the response of the large language model (LLM) to generate accurate answers.
For example, you can leverage RAG to create an AI application that answers questions about benefits available for employees at your company. In this case, a vector database created from internal documents on employee benefits would supply relevant context to the LLM. This would ensure that the responses are accurate and specific to the benefits provided by your company, as opposed to generic responses that the LLM would have otherwise generated.
Another common application is semantic search in which the contextual meaning and intent of a search query is used to perform the search, as opposed to matching keywords present in the query and the documents. Other applications include recommender systems, image retrieval, anomaly detection, and conversational AI, or chatbots.
Getting started with vector databases
- Research current applications of vector databases to understand the landscape and gain insight into how other organizations are using them to solve real-world problems.
- Identify current challenges present within your organization and the potential benefits of using vector databases for those.
- Evaluate your data ecosystem, including the data available and the existing infrastructure. Assess the structure, the complexity, the quality, the volume, and the velocity of the available data.
- Pick a simple and well-defined use-case for prototyping where semantic similarity is important (eg. search).
- Choose a vector database from multiple options, including proprietary solutions (eg. Weaviate) and open-source solutions (eg. Milvus). Consider the features needed for integrating it as part of your data ecosystem.
- Build and evaluate the pilot project. Iterate based on the evaluation metrics and the feedback received.
- Scale and expand to other use-cases.
Final thoughts
Vector databases are here to stay and their adoption will only increase with the increasing development in AI. Gartner estimates that by 2026, more than 30% of enterprises will have adopted vector databases. Will you be one of them?




