You have 1 article left to read this month before you need to register a free LeadDev.com account.
Has your performance calibration process turned toxic?
A performance calibration is any process in which managers come together to compare employee performance against each other to drive consistency across a team, an org, or a company.
In an ideal world, performance calibrations can be an incredibly helpful tool. They can help to make sure people are being treated fairly across the company. They can also give new managers a feel for what the bar is for each level. They provide a way for managers to collaborate on how best to approach delivering performance reviews. And they can help catch potential mistakes, especially when folks are being underrated.
However, in the real world, calibration processes tend to fall somewhere along what I call the ‘slippery slope’.
The slippery slope of performance calibrations
Even with the best intentions, calibration processes can quickly become very toxic. They require a lot of time and money, often involving hours-long meetings full of engineering leaders, with those leaders doing hours of preparation in advance. Because of the high cost, companies might cut corners in an effort to get the most bang for their buck. This is almost always a mistake.
Here are the three stages of the slippery slope that occur as a result:
Stage 1: Dissociation and fungibility
Because each round of calibration is expensive, companies try to keep the number of rounds to an absolute minimum – often only one or two. While that might work for a smaller company, it’s going to cause trouble once the company grows past a couple of hundred employees.
The larger the group of people, the harder it is to have a holistic understanding of each person and their performance. It’s hard enough to have that deep of an understanding of the people on your team, let alone dozens or even hundreds of people. This leads to shortcuts.
The company can either reduce the number of people that they’re calibrating by trying to focus on certain groups (like high performers), or distill a person’s performance and context into a bite-sized chunk. Often, this looks like performance ratings, plus a little blurb highlighting strengths, weaknesses, and evidence of their impact.
Adding a layer of abstraction dissociates employees from their performance, which leads to senior leaders believing that employees are interchangeable. On the other hand, reducing the number of people being calibrated significantly decreases the efficacy of calibrations, as there’s a group of people who have no idea whether their ratings are fair. Neither are good substitutes for investing the proper amount of time in the calibration process.
But how do we know if we’re doing a good job? Enter the performance curve.
Stage 2: Performance curves
Calibrations are a highly subjective process. Performance curves are an attempt to make it more objective. The idea is simple. For a large enough group of employees, employee performance will fall under a normal distribution:
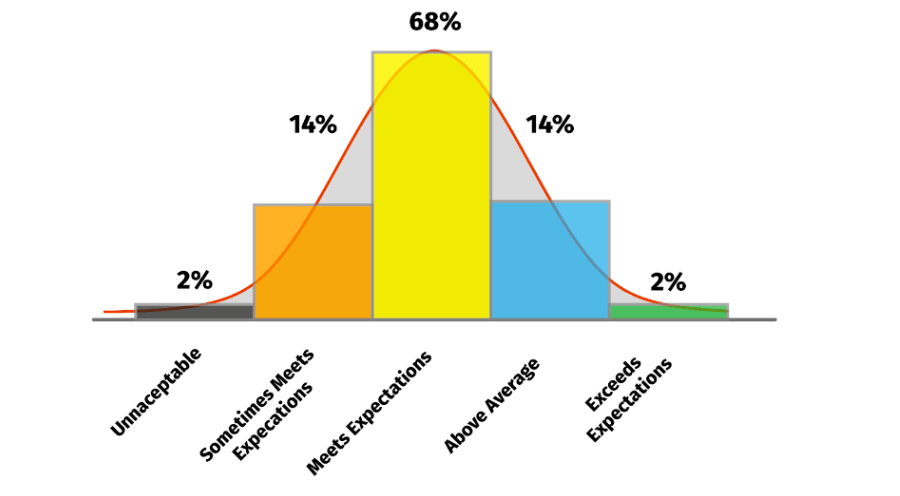
This theory sounds reasonable because it shows that most people (almost 70%) perform at an average or mid-level. It also sounds reasonable because we know that there have to be people who are close to getting a promotion and that there’s probably somebody performing below the average. But it actually makes a lot of assumptions that people might not think about.
For instance, junior engineers tend to spend less time in-level before getting promoted. So a ‘normal’ performance curve for them might look like this:
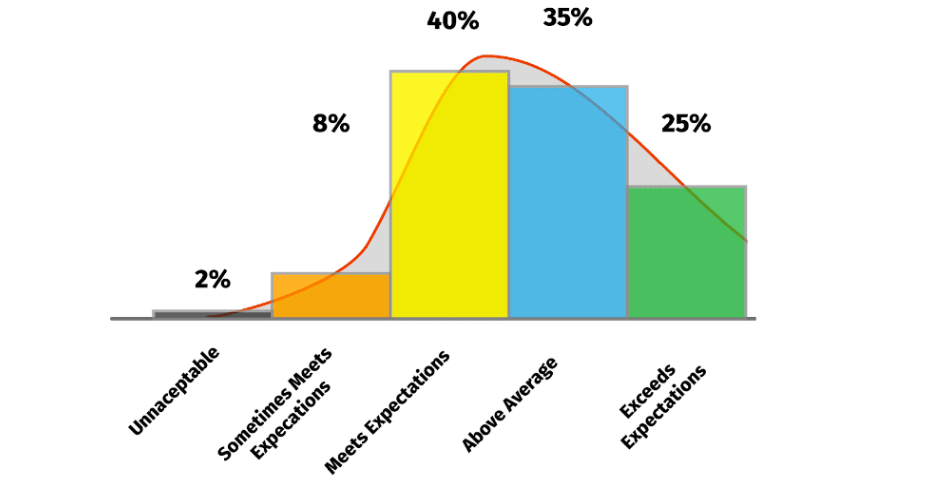
Things like level and tenure play a huge role in what a truly normal distribution should look like.
A lot of companies offer a performance curve as guidance, or as a way of framing a debate. But the biggest danger is when companies start trying to fit their ratings to the curve. Managers will start to hear, ‘We have too many people marked as exceeding expectations. Not everyone can be exceeding expectations.’ This leads to one of two outcomes: either managers will adjust people’s performance ratings to fit the curve, or the company will decide that its expectations of its employees are too low and they need to be held to a higher standard.
Both of those outcomes amount to as near as makes no difference stack ranking.
Stage 3: Stack ranking
This is the final stage of the slippery slope. With rigid adherence to performance curves, people’s performance becomes relative to others’ performance, not just their own. Because somebody needs to be at the bottom of the curve/stack, a solid developer with average performance could get marked as unsatisfactory because they aren’t performing as well as their peers, who are all performing exceptionally. This leads to the performance management and likely termination of the developer, despite the fact that they were meeting all the expectations for their level.
Performance becomes a zero-sum game. In order for an employee to get recognition, they realize that they have to perform better than their teammates. At best, this creates an environment where people are unwilling to help each other, which reduces productivity and greatly reduces creativity and collaboration. At worst, this creates an environment where employees are incentivized to sabotage one another.
Companies like Microsoft, once a huge proponent of stack ranking, have realized that stack ranking is bad for its employees, it’s bad for morale, and it’s bad for the company. They have adopted performance philosophies that are not zero-sum, and I think they’re better off because of it.
The most unfortunate part of this entire slippery slope is that the people who feel the least empowered to speak out about it are the ones who are disproportionately affected by it, for example women, people who are Black, Latinx, Indigenous, transgender, parents, older, disabled, and other marginalized folks. As I mentioned above, this is because the basal assumption is that people are interchangeable, and they’re just not. But unless the company is actively analyzing its performance data broken down by these groups, they’re unlikely to notice.
So what should we do instead?
Here are some suggestions for keeping calibrations positive and useful:
1. Start calibrations locally
The larger the group of people being calibrated, the more difficult it is to have the appropriate amount of context on each person. I highly recommend doing initial calibrations at a local level. A good example would be a director facilitating a calibration of their org with their managers.
2. Throw out the curve
Performance curves are at best a crutch for companies. They save them from having to do the work of understanding whether they did a good job. Performance curves are so dangerous, in my opinion, that they shouldn’t even be used for ‘guidance’ purposes. I’ve seen how quickly ‘guidance’ can become expectations and requirements.
3. Talk about everyone
In my experience, you can’t predict which employees will cause the most discussion amongst managers. You never know who might benefit from having more pairs of eyes on their performance review. By making sure you include everyone in the process, you allow everyone to benefit from it, and you reduce selection bias.
4. Talk about messaging
One of the most helpful things I’ve seen in calibration processes is an attention toward how the manager is going to message this performance review to their report. This is a combination of making sure that the manager has thought about what their report’s next steps should look like, including areas of growth and opportunity. Not only is this helpful to the manager, but it ensures that their team gets better feedback and coaching.
5. Trust managers
One of the conditions that lead to the slippery slope above is a lack of trust in front-line managers. This can show up in calibration processes, promotion processes, and elsewhere. It’s important to have mechanisms in place that allow you to ‘trust but verify’. For example, if someone is given a very high rating and a promotion, the verification mechanism could happen at the next performance review. Did that person meet at least average expectations for their new role? That’s great. If not, there should be a deeper dive as to what went into the decision of rating them so highly and promoting them. By giving managers this trust (with verification) you can simplify a lot of processes like performance and promotions.
6. Define clear ratings
All too often, the descriptions of what each performance rating means are vague. Maybe a three out of five means ‘meets all expectations’, but a four means ‘meets all expectations, exceeds some.’ How many is some? Would exceeding expectations in one area count? What about in all areas but one? Does that count as ‘exceeds all expectations’? Putting some thought and intention into the wording helps to make assigning ratings less subjective and increases the accuracy of your performance ratings across the company.
7. Analyze and spot trends
And finally, no matter what good things we put in place, it’s important that we’re analyzing our performance and promotion data. Filter by as many different groups of people as possible. Pay close attention to marginalized groups. Spot trends and triage them. Does the trend fit with the company’s performance philosophy? How about their diversity and inclusion efforts? Only by doing this intentional analysis can you really be sure that your calibration process is working in harmony with the company’s goals and philosophies.



